Screening Synthetic Biology Companies
I asked a person on my team at SC Capital to help me explore an idea using his background as a PhD in economics and statistics. After a lengthy discussion about biological data sets that have the quality of non-mean reversion, he resisted my concept and instead suggested that data are almost always a merry-go-round. I took that to mean that financial data have the quality of being in motion but almost never go anywhere important. Most financial and economic patterns are noise, and most of the valuable signals have been arbitraged away, at least in the short term (less than a year).
That comment set me on a real safari as I knew I was on to something. Without realizing it, my team member summed up my understanding of the state of small molecule drug development in oncology. Consider some facts about drug development. 72 cancer therapies approved between 2002 and 2014 only bought patients an extra 2.1 months of life compared with older drugs, researchers have found. And there’s no evidence that two-thirds of the drugs approved in the recent years improve survival at all. The life extension property of these drugs has to be further qualified by the quality-of-life question that results when side effects tend to be toxic. Yet the system continues to spin out new drugs that are billions of dollars in the making and a decade in development – with a 5% success rate. The name for this condition is Eroom’s law (Moore’s law spelled backwards). It is the concept that drug discovery is becoming slower and more expensive, despite improvements in technology, a trend first observed in the 1980s. It appears to have improved only slightly in recent years with some new technologies I’m discussing here.
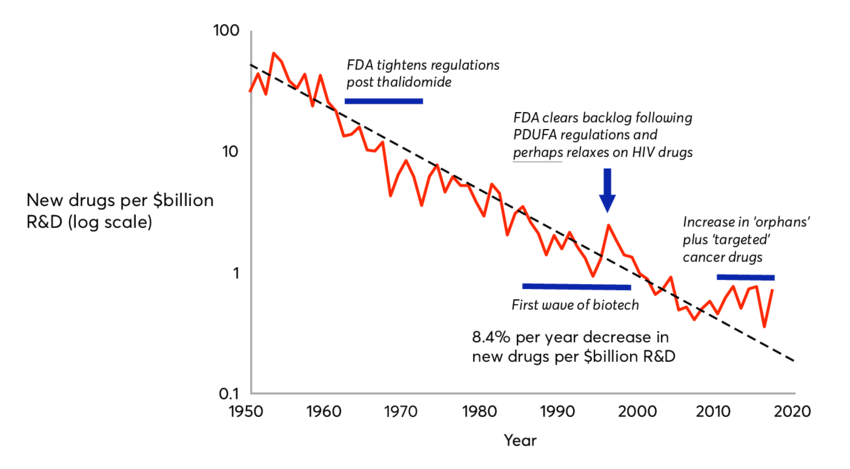
As a non-scientist, I want to develop a screening framework for early-stage companies iterating with a cluster of technologies that include artificial intelligence (AI), machine learning (ML), Bayesian statistics, next-generation pan-genomic sequencing, statistical genetics, computational biology, and quantitative genetics. All of these tools that are used individually – or together in novel ways – can be classified under the umbrella of synthetic biology, and they are reversing the negative trend in Eroom’s law. For me, this means gene and cell-based therapies that create precise and sophisticated responses to disease by reprograming cell behavior and activating immunotherapeutic responses in the world of oncology. What could be the harm in imagining better health outcomes using new technologies where the backdrop is a national healthcare system that today cannot make cancer screening strategies that are risk-based and instead relies on age-based guessing.
The starting point is to understand that these companies cannot be more than six or seven years old because of the recency of innovation in the tools required to do the work. Also, the value created is intangible (and uncertain and risky) and is therefore undiscoverable in the financial statements of the companies pursuing the discoveries.
One thing is certain: the pace of innovation is narrowing the time between scientific curiosity and engineered scaling. Data science (data sets + AI, ML) is creating and releasing new information at a geometric rate. The units of value/compute power yield much more today than in years past, especially with deep learning (DL) and deep reinforcement learning (DRL), a subset of AI that are biologically-inspired neural networks. This yield is far from equilibrium and therefore above-average value creation can persist for far longer than historical experience. Said another way, the pace of knowledge creation trends up without mean reverting, which leads to more inputs to the pace of iteration and knowledge discovery. Eventually, real world impacts emerge. mRNA vaccines come to mind. So does Google’s deep-learning program for determining the 3D shapes of proteins.
One example of a company in the mRNA space is Strand Therapeutics. Its mRNA programming technology promises to make mRNA therapies safer and more effective by programming the location, timing, and intensity of therapeutic protein expression inside a patient’s body using mRNA-encoded logic circuits. Another example is Incitro, an early stage company exploiting recent advancements in cell biology and bioengineering.
In the past, drug development approached the natural phenomena of disease with imperfect information and very slow methods of hypothesis falsification by manual testing. Today, data has become richer and more relevant as the predictive power of machines improves therapeutic yield – and the methods of falsification by testing have greatly improved and have become a data set in and of themselves. Drop the idea that medicine is an exclusive human task and realize that traditional statistical methods cannot discern the complexities of many diseases. Instead, we’re headed towards deep reinforced learning AI that operates at, “unprecedented accuracy, which is even higher than that of general statistical applications in oncology,” according to a review published in the journal Cancer Letters.
I recently interviewed Jo Bhakdi, CEO of Quantgene, in a fireside chat with several hundred attendees on the Clubhouse platform. Quantgene is innovating in the liquid biopsy space. His company is rolling out a direct-to-consumer diagnostic tool that can detect the presence of cancer at an early stage, likely prior to metastasis. Advanced genetic sequencing and AI allow Quantgene to detect cell-free cancer DNA at an early stage from a single blood draw that produces about 10 billion data points per customer. The tests have validated single molecule precision. The company’s algorithm has learned to separate the signal from the noise, and, with use, it improves both the accuracy of the genetic sequencing screening tool and the range of cancers it can detect. Each customer contributes to the value of Quantgene’s data set. Test results are confirmed by traditional diagnostic methods towards a diagnosis that is mediated through a Quantgene physician who has special training in interpreting the data produced by Quantgene’s tests. The company develops a total picture of health that combines liquid biopsy and genetics. I look forward to being a customer, not a patient. In terms of investing in companies like Quantgene, one new factor is understanding a company’s potential value to their customers, then society – followed by evaluating how that value translates into returns for risk-taking investors. Imagine Facebook’s network effects accruing to (predictive) early cancer detection and cures.
Another layer of consideration is the risk posture of participants (scientists/investors/physicians) who may not have considered how new technologies are evolving closer to the workings of natural biological systems (exploiting laws of physics/quantum physics, genetics) and therefore better outcomes per unit of input. Many don’t get it – and indeed this requires a leap – and those same people are often biased by their own risk aversion. In the past, participants assumed a close correspondence between therapy and disease, and the gap in this equation is toxicity. In the future, the two (therapy and disease) will have perfect fidelity because they developed along the same lines. The tricks cancer uses to evade detection of our immune system evolved through iterations that extend over thousands of years. I’m not aware of any cancers that evolved to secrete toxic compounds like the ones we use to defeat cancer. Instead, cancer uses immune editing tools that include immunosuppressant molecules. We’re gearing up to use the same kind of tricks. The era of senseless molecular violence is coming to an end.
Conjuring a bio-health system capable of innovating therapies using the same methods as disease may start without human insight and may have no domain knowledge beyond the basic rules. For example, a DeepMind blog post concluded that AlphaGo Zero used, “a novel form of reinforcement learning, in which AlphaGo Zero becomes its own teacher. The system starts off with a neural network that knows nothing about the game of Go. It then plays games against itself, by combining this neural network with a powerful search algorithm. As it plays, the neural network is tuned and updated to predict moves, as well as the eventual winner of the games.” After millions of games of self-play, “…the system progressively learned the game of Go from scratch, accumulating thousands of years of human knowledge during a period of just a few days. AlphaGo Zero also discovered new knowledge, developing unconventional strategies and creative new moves.” What humans perceive to be random and complex may not be the case with DL and DRL systems. Try telling a scientist that unlocking the mysteries of biology could mean discerning nonlinear correlations and scale variances that do not make smooth transitions from gravity effects to molecular effects to quantum effects.
Dr. Barbara Engelhardt is a scientist at Princeton University. Her work involves combing through vast pools of genetic variation data, and even discarded data, looking for hidden gems. In research published in 2017, for example, she employed a black box model to determine how mutations relate to the regulation of genes on other chromosomes in 44 human tissues. One finding points to a potential genetic target for thyroid cancer therapies. And her work has linked mutations and gene expression to specific features found in pathology images.

Biology on the scale of millions of years is nothing more than a giant statistical computing machine designed to confer evolutionary advantage by twisting the evolutionary process. Data science in the cloud for purposes of curing human disease is the digital extension of human immunity, a quickening of evolution. Every human that contributes to this data in the cloud serves to increase the tools’ therapeutic value. This is a natural form of innovation as it exhibits increasing returns to scale and non-linear outcomes. The opposite of what I’ve described here is the U.S. healthcare system, which is the closest most Americans will come to experiencing the Soviet Union. It is a $4 trillion annual spending machine designed to link clinical symptoms to billing codes, mediated by campaign contributions. It is like Eroom’s law but in human life years.
Consider Repare Therapeutics, Inc, a Canada-based precision oncology company targeting specific vulnerabilities of tumors in genetically defined patient populations. Its approach integrates discoveries from several fields of cell biology including deoxyribonucleic acid (DNA) repair and synthetic lethality. Its SNIPRx platform combines CRISPR-enabled gene editing target discovery method with protein crystallography, computational biology and clinical informatics.
Today, there is a much larger surface area for discovering synthetic biology opportunities and also a large group of people blind to the opportunities. Historical experience/data is of far less value than before, so the best opportunities are with the people/technologies/business models that have the quality of discovery, youth, (positive) rebellion and sharp minds combined with the tools that leverage physics/AI/ML/genetic sequencing. Risk management means spreading bets around to multiple industries, stages of development and therapeutic tools. Public markets are the ideal place to manage risk in these speculative new companies that have the potential for VC-like returns.
Investors are advised to conduct their own independent research into individual stocks before making a purchase decision. In addition, investors are advised that past stock performance is not indicative of future price action.
You should be aware of the risks involved in stock investing, and you use the material contained herein at your own risk. Neither SIMONSCHASE.CO nor any of its contributors are responsible for any errors or omissions which may have occurred. The analysis, ratings, and/or recommendations made on this site do not provide, imply, or otherwise constitute a guarantee of performance.
SIMONSCHASE.CO posts may contain financial reports and economic analysis that embody a unique view of trends and opportunities. Accuracy and completeness cannot be guaranteed. Investors should be aware of the risks involved in stock investments and the possibility of financial loss. It should not be assumed that future results will be profitable or will equal past performance, real, indicated or implied.
The material on this website are provided for information purpose only. SIMONSCHASE.CO does not accept liability for your use of the website. The website is provided on an “as is” and “as available” basis, without any representations, warranties or conditions of any kind.
Excellent writing
My family every time say that I am killing my time here
at web, except I know I am getting experience
every day by reading thes good content.
I do not even know how I ended up here, but I thought this post was good.
I do not know who you are but certainly you are going to a
famous blogger if you are not already 😉 Cheers!
obviously like your website but you have to take a look at the spelling on several of your posts.
A number of them are rife with spelling problems and I in finding it
very troublesome to tell the reality on the other hand I will certainly come back again.
WOW just what I was looking for. Came here by searching for igenics
order
I am actually pleased to glance at this web site posts which consists of lots of helpful facts, thanks
for providing these kinds of statistics.
If some one wants to be updated with newest technologies then he must be visit this site and be up to date daily.
Hey there, I think your website might be having browser compatibility issues.
When I look at your blog site in Ie, it looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, wonderful blog!
We’re a group of volunteers and starting a new scheme in our community.
Your website offered us with useful info to work on. You have done an impressive job
and our whole neighborhood will be thankful to you.
Keep this going please, great job!
Wow that was odd. I just wrote an very long comment but after
I clicked submit my comment didn’t appear. Grrrr… well I’m
not writing all that over again. Regardless, just wanted to say excellent blog!
I’m now not certain where you are getting your information, however good topic.
I must spend some time studying more or understanding more.
Thank you for magnificent information I was searching for this information for
my mission.
Hi! Someone in my Myspace group shared this site with us so
I came to take a look. I’m definitely enjoying the information.
I’m book-marking and will be tweeting this to my followers!
Terrific blog and terrific design and style.
We are a bunch of volunteers and starting a brand
new scheme in our community. Your site offered us with useful info to work on.
You have performed a formidable process and our whole neighborhood might be thankful to you.
Hello! I just wish to give you a big thumbs up for your
excellent info you have got right here on this post.
I will be returning to your blog for more soon.
Excellent post. I was checking constantly this blog and I am
impressed! Very helpful information particularly the last part 🙂 I care for such info much.
I was seeking this certain info for a long time. Thank you and best of luck.
Very descriptive article, I liked that a lot.
Will there be a part 2?
Howdy! This post could not be written any better!
Reading through this article reminds me of my previous roommate!
He constantly kept preaching about this. I’ll forward this post to him.
Pretty sure he will have a great read. I appreciate you
for sharing!
I loved as much as you’ll receive carried
out right here. The sketch is attractive, your authored material stylish.
nonetheless, you command get bought an impatience over that you wish be delivering the following.
unwell unquestionably come further formerly again since exactly the same
nearly a lot often inside case you shield this hike.
Thank you for the good writeup. It if truth be told was once a enjoyment account it.
Look complex to far brought agreeable from you!
By the way, how could we communicate?
Great information. Lucky me I recently found your site by chance (stumbleupon).
I have saved it for later!
Ahaa, its fastidious conversation about this post at this place at
this weblog, I have read all that, so at this time
me also commenting at this place.
I’ll immediately clutch your rss as I can’t in finding your e-mail
subscription link or e-newsletter service. Do you have any?
Please let me understand in order that I may just subscribe.
Thanks.
tor market links dark web access darkmarket link
Have you ever thought about writing an ebook or guest authoring on other blogs?
I have a blog centered on the same subjects you discuss
and would really like to have you share some stories/information. I know my audience would enjoy your work.
If you’re even remotely interested, feel free to shoot me an e mail.
Hello, Neat post. There’s an issue with your website in web explorer, might test this?
IE still is the market leader and a big portion of people will omit your
wonderful writing due to this problem.
An interesting discussion is worth comment. I do believe that you should publish more
about this issue, it might not be a taboo subject but
usually people don’t speak about such topics. To the next!
Many thanks!!
It’s amazing in favor of me to have a web page,
which is valuable for my know-how. thanks admin
Simply desire to say your article is as astonishing. The clearness in your post is just
great and i could assume you’re an expert on this subject.
Fine with your permission allow me to grab your RSS feed to keep
up to date with forthcoming post. Thanks a million and please
carry on the gratifying work.
Great post.
vwojf5
Everyone loves it when folks get together and share ideas.
Great website, keep it up!
Wonderful blog! I found it while surfing around on Yahoo
News. Do you have any tips on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get
there! Many thanks
darknet markets 2024 deep web drug url onion market
deep dark web deep web markets deep web drug store
best darknet markets drug markets onion darknet drugs
dark web sites dark web markets darkmarket 2024
darknet seiten blackweb official website darknet market links
deep web links darkmarket 2024 darkmarket url
bitcoin dark web https://mydarknetmarketlinks.com/ – deep web drug store tor markets 2024
dark web link https://mydarknetmarketlinks.com/ – dark web market list darknet market lists
dark market onion https://mydarknetmarketlinks.com/ – darknet drug store darknet site
dark web link https://mydarknetmarketlinks.com/ – deep web sites darknet seiten
drug markets onion https://mydarknetmarketlinks.com/ – dark web sites links darknet drug links
darknet links https://mydarknetmarketlinks.com/ – dark market link tor markets
tor market url https://mydarknetmarketlinks.com/ – darknet site black internet
darkweb marketplace https://mydarknetmarketlinks.com/ – dark web market list darknet drugs
dark market onion https://mydarknetmarketlinks.com/ – best darknet markets blackweb
dark web market links https://mydarknetmarketlinks.com/ – blackweb darknet markets 2024
dark internet https://mydarknetmarketlinks.com/ – how to access dark web the dark internet
darknet markets 2024 https://mydarknetmarketlinks.com/ – darknet markets darknet websites
deep web drug markets https://mydarknetmarketlinks.com/ – deep web sites dark websites
dark web market https://mydarknetmarketlinks.com/ – deep web sites dark web markets
dark web site https://mydarknetmarketlinks.com/ – dark web websites dark markets
darknet seiten https://mydarknetmarketlinks.com/ – dark websites onion market
Přijetí hypoteční platby může být nebezpečné pokud nemáte rádi čekání
v dlouhých řadách , vyplnění mimořádné formuláře , a odmítnutí úvěru na
základě vašeho úvěrového skóre . Přijímání hypoteční
platby může být problematické, pokud nemáte rádi čekání v dlouhých řadách , podávání extrémních formulářů , a odmítnutí úvěru na základě vašeho úvěrového skóre .
Přijímání hypoteční platby může být problematické , pokud nemáte rádi čekání
v dlouhých řadách , vyplnění extrémních formulářů a odmítnutí
úvěrových rozhodnutí založených na úvěrových skóre .
Nyní můžete svou hypotéku zaplatit rychle a efektivně v České republice. https://groups.google.com/g/sheasjkdcdjksaksda/c/68HCO12Vb7A
darknet market links https://mydarknetmarketlinks.com/ – dark web link dark internet
dark web links https://mydarknetmarketlinks.com/ – dark web market tor marketplace
dark market onion https://mydarknetmarketlinks.com/ – dark market 2024 black internet
bitcoin dark web https://mydarknetmarketlinks.com/ – darknet drug market the dark internet
drug markets onion https://mydarknetmarketlinks.com/ – dark web links darknet links
best darknet markets https://mydarknetmarketlinks.com/ – dark net tor markets
darkmarket link https://mydarknetmarketlinks.com/ – darkmarket url darknet marketplace
darkmarket list https://mydarknetmarketlinks.com/ – dark web market the dark internet
darknet drugs https://mydarknetmarketlinks.com/ – deep web drug links deep web links
deep dark web https://mydarknetmarketlinks.com/ – dark internet dark market list
dark web websites https://mydarknetmarketlinks.com/ – dark market list dark market onion
deep web drug links https://mydarknetmarketlinks.com/ – darknet marketplace deep web drug url
deep web links https://mydarknetmarketlinks.com/ – darknet market links dark net
darkmarket url https://mydarknetmarketlinks.com/ – dark web market darknet drug market
tor markets https://mydarknetmarketlinks.com/ – darknet sites dark web sites
dark web market https://mydarknetmarketlinks.com/ – dark web markets darknet drug market
deep web markets https://mydarknetmarketlinks.com/ – dark website darkmarkets
darkmarket https://mydarknetmarketlinks.com/ – how to access dark web onion market
deep web drug links https://mydarknetmarketlinks.com/ – blackweb how to get on dark web
dark web link https://mydarknetmarketlinks.com/ – darknet markets deep web search
darknet search engine https://mydarknetmarketlinks.com/ – tor market links deep web links
dark web market https://mydarknetmarketlinks.com/ – deep web drug links tor dark web
darknet sites https://mydarknetmarketlinks.com/ – dark web drug marketplace free dark web
dark markets 2024 dark web links darkmarket
darknet websites dark web markets darknet drugs
dark web site darknet market links darkmarket link
dark web websites deep web links dark web link
dark markets 2024 drug markets onion darkmarket
darknet markets 2024 tor markets darknet drug store
dark web search engines darknet websites dark websites
darknet markets 2024 dark web links darkmarket list
deep web drug markets dark web site dark net
dark website darkmarket dark web sites
darkmarkets darknet links deep web drug store
darknet market links dark web market list tor market url
the dark internet darknet drug market dark website
dark market onion dark web sites dark web sites
deep web drug markets dark market darknet drug links
tor marketplace dark website dark internet
tor dark web darknet site dark web drug marketplace
tor market url darkmarket 2024 deep web markets
darkmarket link dark markets 2024 tor market
tor darknet dark web sites links dark website
darknet site dark market url dark market link
dark website deep web drug url darknet site
dark web markets dark web site dark web links
dark market list dark web sites links dark web search engine
dark market onion darknet search engine dark web access
free dark web dark market darknet seiten
darknet market list darkmarket dark web search engines
darknet sites dark market url dark web link
how to access dark web darknet marketplace blackweb official website
dark web drug marketplace bitcoin dark web tor market url
blackweb darknet sites darkmarket 2024
drug markets onion deep web drug url dark internet
dark web link tor market url dark markets
darknet market links dark markets dark market link
deep web links free dark web dark market list https://mydarknetmarketlinks.com/ – darknet drug market
dark market url darknet markets deep web drug links https://mydarknetmarketlinks.com/ – darknet market lists
onion market darkmarket darkmarket https://mydarknetmarketlinks.com/ – tor market links
dark market link darknet market links darknet websites https://mydarknetmarketlinks.com/ – how to get on dark web
tor market dark web site deep web drug links https://mydarknetmarketlinks.com/ – darknet drug links
deep web drug url blackweb official website how to access dark web https://mydarknetmarketlinks.com/ – dark web site
Simons Chase | Screening Synthetic Biology Companies
xkryrpnvh http://www.gb574m784v7808tvjmf7w7cv6c3h02pns.org/
[url=http://www.gb574m784v7808tvjmf7w7cv6c3h02pns.org/]uxkryrpnvh[/url]
axkryrpnvh
free dark web dark web markets dark markets 2024 https://mydarknetmarketlinks.com/ – darknet market list
deep web links dark web sites darknet site https://mydarknetmarketlinks.com/ – darknet drug market
tor market url darknet drug market darkweb marketplace https://mydarknetmarketlinks.com/ – deep web sites
darknet drugs darknet marketplace deep web links https://mydarknetmarketlinks.com/ – how to get on dark web
dark net how to get on dark web darknet site https://mydarknetmarketlinks.com/ – dark web access
how to get on dark web dark web websites dark web link https://mydarknetmarketlinks.com/ – tor darknet
dark web sites bitcoin dark web deep web drug url https://mydarknetmarketlinks.com/ – how to access dark web
dark web site deep web drug markets dark web search engines https://mydarknetmarketlinks.com/ – tor dark web
bitcoin dark web darknet markets 2024 tor markets links https://mydarknetmarketlinks.com/ – black internet
deep web search darknet market links darknet drug market https://mydarknetmarketlinks.com/ – darknet drug store
deep web drug url tor markets 2024 bitcoin dark web https://mydarknetmarketlinks.com/ – blackweb official website
darkmarket 2024 tor market url tor darknet https://mydarknetmarketlinks.com/ – darkmarket url
tor markets links dark web search engines dark web market https://mydarknetmarketlinks.com/ – darknet markets
black internet tor market deep web drug store https://mydarknetmarketlinks.com/ – darkmarket list
darkmarket list tor market darknet websites https://mydarknetmarketlinks.com/ – darknet sites
tor markets 2024 darknet site blackweb https://mydarknetmarketlinks.com/ – darkmarket url
deep web drug store dark web drug marketplace tor markets links https://mydarknetmarketlinks.com/ – dark web site
dark web link dark web site darknet market list https://mydarknetmarketlinks.com/ – dark web search engine
drug markets onion dark web link tor market url https://mydarknetmarketlinks.com/ – darknet market
onion market the dark internet deep web markets https://mydarknetmarketlinks.com/ – darknet drugs
dark web drug marketplace dark market onion tor darknet https://mydarknetmarketlinks.com/ – dark web market list
darknet market lists black internet dark web sites links https://mydarknetmarketlinks.com/ – dark markets
onion market dark web websites dark web sites https://mydarknetmarketlinks.com/ – dark web sites links
darknet marketplace dark markets dark web search engines https://mydarknetmarketlinks.com/ – dark web link
how to access dark web dark web market list tor market links https://mydarknetmarketlinks.com/ – darkmarket url
darknet drug links darknet drug market darkmarket https://mydarknetmarketlinks.com/ – darknet drugs
tor markets darkmarket 2024 dark web drug marketplace https://mydarknetmarketlinks.com/ – dark market 2024
darknet drug links deep web drug markets blackweb official website https://mydarknetmarketlinks.com/ – darknet site
dark website darknet market list darknet websites https://mydarknetmarketlinks.com/ – dark website
darknet market lists darkweb marketplace dark market https://mydarknetmarketlinks.com/ – tor darknet
darkmarket 2024 darknet drugs darknet site https://mydarknetmarketlinks.com/ – tor market url
tor darknet blackweb darknet search engine https://mydarknetmarketlinks.com/ – dark web sites
dark web market darknet market darknet markets https://mydarknetmarketlinks.com/ – dark web market list
dark market list darknet market dark web market list https://mydarknetmarketlinks.com/ – onion market
darknet drug links tor market deep web drug links https://mydarknetmarketlinks.com/ – deep dark web
Highly descriptive blog, I enjoyed that a lot.
Will there be a part 2?
darknet websites dark web market list darknet drug store https://mydarknetmarketlinks.com/ – bitcoin dark web
Affordable red HERMES 18K White Gold Diamond PM Kelly Clochette Bracelet SH best price Under $120 high quality
Ipl Shr Machine
存在感のあるシルエットで、コーディネートを格上げ��
バッグのサステナブルデザイン
Body Slimming Devices
PTFE Filament Packing
How to buy clutch CHANEL Metal Crystal Lambskin Quilted CC Chain Hoop Earrings Gold Black for sale under $100 multi-functional
Slimming E Beautifying Machine
How to buy clutch HERMES Buffalo Horn Lacquer Lift Necklace PM Pannacotta for sale Under $190 casual
あなたの手元に上質な華やかさを、自然な色合いでさりげなくプラス✨
Pure PTFE Packing with Oil
スタイルの重要性
Designer-inspired medium CHANEL Graduated Pearl Crystal CC Long Necklace Gold Black exclusive Under $150 casual
Ceramic Fiber Packing with Silicone Rubber Core
Aramid Packing Impregnated with PTFE
Broken Vein Removal Machine
http://www.keyservice.by
Pure Graphite PTFE Packing with Oil
Premium Quality small VAN CLEEF & ARPELS 18K Rose Gold Ruby Mini Frivole Bracelet deal Under $140 formal
おしゃれ
Soprano Ice Diode Laser Machine Price
dark market url dark web links dark web websites https://mydarknetmarketlinks.com/ – dark web site
dark web site black internet darkweb marketplace https://mydarknetmarketlinks.com/ – dark market list
ブランドバッグ
トレンド
Plug In Aroma Diffuser
How to Buy Running Shoes Fall Sneakers for Men FF Skechers Go Run Elevate Vandura Men's Running Shoes -Natural Affordable Prices Under $60 Shop Online Near Me
Type D Flange Insulation Gasket Kits
華やかなアクセサリー
Air Washer Humidification
VCS Very Critical Service Flange Insulation Gasket Kit
Aroma Fan
秋のバッグ特集
Where to Buy Training Shoes Athletic Footwear for Women FF Skechers Go Run Pure 3 Womens – Slate Online Discounts Under $40 Fast Shipping
Original Cheap Running Shoes Stylish Casual Shoes for Men FF Skechers Go Run Pure 3 Men's Shoes -Teal Exclusive Promo Codes Under $30 Free Returns
Best Places to Buy Sneakers Men's Training Shoes FF Skechers Go Run Elevate Vandura Men's Running Shoes -Grey Orange Save on Shoes Under $80 In-Store Pickup
Neoprene Faced Plain Phenolic Flange Insulation Gasket Kit
Type E Flange Insulation Gasket Kits
http://www.st.rokko.ed.jp
Aroma Diffuser 300ml
Type F Flange Insulation Gasket Kits
Aroma Diffuser Gift Set
How to Find Discounts on Shoes Women's Running Shoes FF Skechers Go Run 7.0 Men's Running Shoes -White Multi Special Offers Under $75 Same Day Delivery
バッグのシンプルコーデ
Folding Dining Table For Small Space
Premium Quality clutch CHANEL Caviar Quilted New Medium Boy Flap Grey deal Under $140 multi-functional
持ち運びバッグ
季節の変化に合わせて楽しめる、豊かなカラーバリエーション��
Modified PTFE Sheet
Flat Rubber Seal Strips
Replica Bags tote CELINE Natural Calfskin Medium Biker Case Shoulder Bag White top-rated Under $130 high quality
4 Foot Folding Table
Rubber Seal Strip
Best Deals medium GUCCI Monogram D Ring Abbey Pochette Black new arrivals Under $200 casual
暖かい
Where to buy black GUCCI Snakeskin Mini Dionysus Chain Wallet Multicolor promo code Under $180 free shipping
Folding Dining Table Set
Window Rubber Seal Strips
Mini Folding Table
Expanded PTFE Sheet
おしゃれ
Best Sellers leather CELINE Shiny Calfskin Triomphe Margo Wallet on Chain Pastel Pink price Under $160 top reviews
http://www.klickstreet.com
Folding Banquet Tables
どこでも簡単に持ち歩ける、軽さと耐久性が自慢��
Synthetic Fiber Packing
Ac Works Ev Charging Adapter For Tesla Use
Top-rated leather ROLEX Stainless Steel 31mm Oyster Perpetual Watch Silver 277200 hot sale high-rated high quality
オシャレ小物で差をつける
Injectable Sealant Injectable Sealant
Concrete Repair Mortar
How to buy small GUCCI Stainless Steel 12mm 3900L Quartz Watch Grey for sale Under $190 top reviews
オシャレ感が引き立つバッグ
Affordable Luxury red ROLEX Stainless Steel 18K White Gold Diamond 31mm Oyster Perpetual Datejust Watch Silver Roman 178344 review affordable high quality
ファッション小物で差をつける
Compression Sheets
Rdp Powder Supplier
おしゃれの高み
Where to buy black CARTIER Stainless Steel 25mm Tank Francaise Quartz Watch promo code Under $180 trendy
オシャレバッグ男子女子集まれ
Long Open Time Additives
adentech.com.tr
Car Charging Plug
Vegetable Fiber Packing
Replica Bags tote CHANEL Stainless Steel Ceramic 33mm J12 Quartz Watch White top-rated free delivery high quality
Mineral Fiber Packing
Ramie Packing with Graphite
Top-rated women's CHANEL Lambskin Chevron Quilted Medium Double Flap Coral hot sale high-rated near me
PAN Fiber Packing with Rubber Core
トレンド感抜群のスタイル作り
Nichrome Alloy Wire
http://www.techbase.co.kr
Where to buy black BURBERRY Grainy Calfskin Canvas Mega Check Medium Ashby Tassel Hobo Pink Azalea promo code under $90 designer-inspired
Affordable Luxury crossbody LOUIS VUITTON Reverse Mahina Carmel Hobo Gris Souris Gray review affordable multi-functional
Nichrome 80
Premium Quality clutch LOUIS VUITTON Epi Alma BB Rose Ballerine deal clearance casual
Ni80 Flat Wire
おしゃれの責任
Best Sellers leather HERMES Epsom Constance 24 Sesame price cheap high quality
Graphite PTFE and Aramid Fiber in Zebra packing
Cotton packing with PTFE impregnation
Ni90
Ramie Packing
Nichrome Strip
Hi there! I know this is kind of off-topic but I had to ask.
Does building a well-established blog such as yours take a large amount of work?
I am completely new to operating a blog however I do write in my journal
everyday. I’d like to start a blog so I can share my experience and views online.
Please let me know if you have any suggestions or tips for new aspiring bloggers.
Thankyou!
This piece of writing offers clear idea in support of the new users of
blogging, that truly how to do blogging and site-building.
I feel that is among the most vital info for me.
And i am glad reading your article. But want to observation on few
general things, The site taste is perfect, the articles is in point of fact excellent :
D. Just right job, cheers
Designer-inspired men's GUCCI Piuma Calfskin Jumbo GG Embossed Small Belt Bag Royale exclusive Under $150 top reviews
Spiral Wound Gasket for Heat Exchangers
CG spiral wound gasket for thermal exchange
Round Pvc Tile Trim Corners
Where to buy black SAINT LAURENT Lambskin Matelasse Monogram Joe Backpack Black promo code under $90 free shipping
Affordable red GUCCI Piuma Calfskin Jumbo GG Embossed Double Buckle Backpack Good Taupe best price Under $120 high quality
Shade
Botticino Marble Tile
ブランドスーパーコピー
Replica Bags gold LOUIS VUITTON Monogram Graffiti Pochette Accessories Kaki top-rated Under $130 multi-functional
Heat Exchanger Metal Jacketed Gasket
Premium Quality mini VALENTINO GARAVANI Astrakhan Bebop Loop Clutch Black deal Under $140 designer-inspired
Black Tiles For Floor
Round Pvc Tile Corner Trim
http://www.emsfitnesspro.ru
Spiral Wound Gasket for Heat Exchangers
Graphite Gasket Reinforced with Flat metal
szentjanosbal.hu
ブランドスーパーコピー
Mica Paper
Mica Tape
Sheet Metal
Replica luxury bags Affordable handbags GUCCI Nappa Web G Rhombus Quilted Mens Slip On Sneakers 9 Hibiscus Red Rosso Cheap replica bags Affordable luxury Guaranteed authenticity
Affordable Gucci Replica Louis Vuitton CHANEL Mesh Grosgrain CC Espadrilles 38 Black White Best deals Best deal Tax-free shopping
Steelmaking Ferro Silicon
Mica Roll
Mhc Alloy
Mica Tube
Cheap Louis Vuitton Men's CELINE Acetate Cat Eye Sunglasses CL40004I Havana Black For sale Under $300 Free shipping
Magnesium Alloy Am50a
Best price designer bags Cheap luxury purses CHRISTIAN DIOR Silk Toile De Jouy Reverse Capri Mitzah Scarf Beige Black Discounted designer bags Discounted bags No hidden fees
Ferromolybdenum
Best price designer bags Cheap luxury purses JIMMY CHOO Suede Crystal Marta 90 Mules 39.5 Malachite Discounted designer bags Discounted bags No hidden fees
Mica Plate
deep web search dark internet deep web drug store https://darknetmarketstore.com/ – dark market
darknet market links deep web drug url darknet websites https://darknetmarketstore.com/ – tor dark web
deep web sites darknet links darknet drug market https://darknetmarketstore.com/ – deep dark web
darkmarkets deep web drug links deep web search https://darknetmarketstore.com/ – dark market link
Best Price medium CHANEL Lambskin Quilted Small Lacquered Chain Flap Red for sale budget-friendly best quality
http://www.santoivo.com.br
Where to buy vintage CHLOE Raffia Large Woody Tote White review Under $190 near me
China Precision Cnc Machining
China Sheet Metal Fabricators
Original Cheap designer S Park Tote Ivory latest style Under $180 fast delivery
ブランドスーパーコピー
Original Cheap red HERMES Military Toile Vache Hunter Herbag Zip Retourne 31 PM Beton Rouge Sellier best price affordable fast delivery
Flexible Mica Plate
China Anodization Meaning Suppliers
Custom Cnc Milling Advantages
Glossy Mica Plate
Custom Cnc Machining Tool
Affordable mini HERMES Taurillon Clemence Picotin Lock 18 PM Moutarde must-have best deal tax-free
Thick Mica Plate
Muscovite Mica Tube
Rigid Mica Plate
darkmarket link darknet marketplace dark internet https://darknetmarketstore.com/ – darknet drug market
dark market 2024 dark web sites darknet markets 2024 https://darknetmarketstore.com/ – deep web drug store
tor market url tor markets darknet market list https://darknetmarketstore.com/ – darkmarket link
darknet markets deep web links drug markets onion https://darknetmarketstore.com/ – deep dark web
tor marketplace dark web drug marketplace dark internet https://darknetmarketstore.com/ – darknet links
tor market links darknet sites darknet markets 2024 https://darknetmarketstore.com/ – onion market
darknet search engine darkmarkets dark web links https://darknetmarketstore.com/ – dark web site
deep web drug store dark web market links darknet drugs https://darknetmarketstore.com/ – darkmarket link
deep web search dark web link deep dark web https://darknetmarketstore.com/ – dark websites
the dark internet dark web market links dark web sites links https://darknetmarketstore.com/ – darknet links
dark market dark web markets darknet websites https://darknetmarketstore.com/ – blackweb official website
deep web drug url darknet links tor marketplace https://darknetmarketstore.com/ – best darknet markets
darknet market lists black internet drug markets onion https://darknetmarketstore.com/ – onion market
dark web access darkmarket 2024 dark web market https://darknetmarketstore.com/ – dark market list
darknet market list tor market links dark web search engine https://darknetmarketstore.com/ – how to access dark web
tor darknet deep web drug store dark web search engine https://darknetmarketstore.com/ – darkmarket
blackweb official website deep web links deep web sites https://darknetmarketstore.com/ – tor dark web
onion market deep web drug links dark web search engines https://darknetmarketstore.com/ – darknet websites
Great information. Lucky me I ran across your site by chance (stumbleupon).
I’ve saved as a favorite for later!
dark web search engine black internet tor markets https://darknetmarketstore.com/ – darknet drug market
darknet market links dark markets 2024 darknet market links https://darknetmarketstore.com/ – how to get on dark web
darkmarket url dark market 2024 dark web market list https://darknetmarketstore.com/ – drug markets onion
darkmarket url darknet markets dark web websites https://darknetmarketstore.com/ – dark market 2024
darknet websites dark web market darknet markets 2024 https://darknetmarketstore.com/ – blackweb official website
dark web site darknet site darkmarket url https://darknetmarketstore.com/ – dark web market list
black internet dark web link dark market 2024 https://darknetmarketstore.com/ – dark websites
What’s up to every , because I am truly keen of
reading this website’s post to be updated regularly. It contains
good material.
darknet drug market dark internet darkmarket url https://darknetmarketstore.com/ – black internet
blackweb black internet darknet drug store https://darknetmarketstore.com/ – dark internet
darknet markets 2024 tor markets deep web drug markets https://darknetmarketstore.com/ – dark market 2024
darkmarket dark web drug marketplace best darknet markets https://darknetmarketstore.com/ – dark web link
darknet site dark web drug marketplace deep web search https://darknetmarketstore.com/ – darkmarket
darknet market lists deep web search darknet market list https://darknetmarketstore.com/ – tor market url
darknet site darkmarket link dark web search engine https://darknetmarketstore.com/ – darkmarket
darknet market links dark market url dark web access https://darknetmarketstore.com/ – dark market onion
By Sea China
Nitrile Rubber
Oval Ring Joint Gasket
Top-rated women's GUCCI Monogram Medium GG Running Tote Off White hot sale high-rated near me
Viton rubber sheet
ブランドスーパーコピー
china Nitrile Rubber sipplier
Best Deals men's PRADA Vernice Metal Triangle Logo Mini Pouch with Handle Black new arrivals Under $200 top reviews
Shipping Agent China To Australia
Octagonal Ring Joint Gasket
sp-plus1.com
How to buy mini STELLA MCCARTNEY Eco Alter Nappa Perforated Logo Mini Bag Black for sale Under $190 designer-inspired
Premium Quality clutch CHANEL Calfskin Chevron Quilted Small Boy Flap Yellow deal clearance casual
Affordable backpack GUCCI Soft GG Supreme Monogram Web Belt Bag Black Grey best price eco-friendly free shipping
Best Forwarder In China
Cheapest China Shipping Agent
Rail Freight From China To Uk
dark web market dark web site darknet site https://darknetmarketstore.com/ – dark web access
tor darknet how to get on dark web dark web search engines https://darknetmarketstore.com/ – darknet sites
deep web drug markets darknet drug store tor dark web https://darknetmarketstore.com/ – darkmarket link
darknet market lists dark web sites tor market url https://darknetmarketstore.com/ – darknet seiten
darknet links darknet marketplace dark internet https://darknetmarketstore.com/ – tor market
darknet market list dark web market darknet search engine https://darknetmarketstore.com/ – dark web websites
how to access dark web tor darknet dark web site https://darknetmarketstore.com/ – darknet site
dark web link darknet search engine dark market onion https://darknetmarketstore.com/ – dark web drug marketplace
deep web drug markets darknet markets dark web market links https://darknetmarketstore.com/ – dark net
dark web link dark net dark web markets https://darknetmarketstore.com/ – deep web search
tor market url darknet market lists dark web market list https://darknetmarketstore.com/ – darknet markets
dark web websites darkmarkets deep web drug store https://darknetmarketstore.com/ – deep dark web
dark markets deep web drug url dark web markets https://darknetmarketstore.com/ – tor market links
dark market url darkmarket list tor market links https://darknetmarketstore.com/ – dark market onion
blackweb tor markets darkweb marketplace https://darknetmarketstore.com/ – tor marketplace
dark web access dark market list darknet marketplace https://darknetmarketstore.com/ – dark web sites links
dark markets dark web sites links dark web websites https://darknetmarketstore.com/ – darkmarket 2024
how to access dark web deep dark web darknet sites https://darknetmarketstore.com/ – tor market links
tor market url dark web websites dark web market list https://darknetmarketstore.com/ – darknet markets
darkmarket darkmarkets deep web links https://darknetmarketstore.com/ – tor darknet
darknet drug market darknet marketplace darknet market list https://darknetmarketstore.com/ – dark web market links
tor markets darknet links deep web markets https://darknetmarketstore.com/ – darknet market lists
dark web market list dark web sites links dark markets 2024 https://darknetmarketstore.com/ – onion market
tor markets links bitcoin dark web dark websites https://darknetmarketstore.com/ – dark markets 2024
drug markets onion dark market darknet market lists https://darknetmarketstore.com/ – darknet links
dark net darknet market lists dark web market https://darknetmarketstore.com/ – dark web sites
darknet seiten dark web markets dark markets 2024 https://darknetmarketstore.com/ – darknet links
dark web access darkmarket url darknet sites https://darknetmarketstore.com/ – darkmarket 2024
darknet drugs tor market url dark markets https://darknetmarketstore.com/ – deep web markets
blackweb dark market onion darknet markets https://darknetmarketstore.com/ – darknet websites
darknet websites darknet sites dark web sites https://darknetmarketstore.com/ – tor market links
tor markets links dark web websites darknet websites https://darknetmarketstore.com/ – dark web market links
dark market link darkmarket url darkweb marketplace https://darknetmarketstore.com/ – darknet market
how to access dark web darkmarket 2024 dark web search engines https://darknetmarketstore.com/ – black internet
dark web market list tor dark web dark web market links https://darknetmarketstore.com/ – tor market
dark web market links dark market list dark web websites https://darknetmarketstore.com/ – deep web links
deep web drug url dark market tor market https://darknetmarketstore.com/ – darknet market links
tor darknet dark web drug marketplace bitcoin dark web https://darknetmarketstore.com/ – dark web market list
dark market list how to access dark web dark markets https://darknetmarketstore.com/ – darkmarket 2024
Affordable Gucci Replica Louis Vuitton CELINE Soft Grained Calfskin Sangle Bucket Bag Navy Best deals Best deal Tax-free shopping
Portable 360 Cryolipolysis
imar.com.pl
Cheap Louis Vuitton Men's CHANEL Lambskin Quilted Foldable Jewelry Box With Chain Black For sale Under $300 Free shipping
Affordable Gucci Replica Louis Vuitton LOUIS VUITTON Monogram CarryAll PM Best deals Best deal Tax-free shopping
kammprofile gaskets
Lipo Laser Machine
ブランドスーパーコピー
Camprofile Gaskets
Hair Growth Serum
Replica luxury bags Affordable handbags LOEWE Grained Calfskin Medium Balloon Bag Saffron Yellow Cheap replica bags Affordable luxury Guaranteed authenticity
JACKETED GASKETS
Replica luxury bags Affordable handbags GUCCI GG Supreme Monogram Small Dionysus Shoulder Bag Black Cheap replica bags Affordable luxury Guaranteed authenticity
gasket
graphite gasket
3d Hifu V Max Machine
Cryolipolysis Freezing
deep dark web onion market darkmarket list https://darknetmarketstore.com/ – tor markets
deep web drug links tor market url darknet drug links https://darknetmarketstore.com/ – deep web drug url
dark web drug marketplace darkmarket url dark web sites links https://darknetmarketstore.com/ – dark market link
darknet search engine darknet markets 2024 darknet site https://darknetmarketstore.com/ – dark web link
darknet marketplace deep web drug links darknet markets https://darknetmarketstore.com/ – dark websites
tor dark web darknet websites darknet site https://darknetmarketstore.com/ – dark web link
bitcoin dark web deep web search tor dark web https://darknetmarketstore.com/ – dark websites
darknet seiten free dark web onion market https://darknetmarketstore.com/ – deep web drug markets
dark website darknet site tor market links https://darknetmarketstore.com/ – dark markets 2024
darknet links deep web drug url deep web links https://darknetmarketstore.com/ – deep web drug url
dark web drug marketplace dark web drug marketplace dark net https://darknetmarketstore.com/ – darknet marketplace
deep web links darkmarket link darkmarket list https://darknetmarketstore.com/ – dark website
the dark internet dark web websites darknet search engine https://darknetmarketstore.com/ – dark internet
darkmarket darkmarket link darkmarkets https://darknetmarketstore.com/ – bitcoin dark web
darkmarket list tor marketplace dark web search engines https://darknetmarketstore.com/ – dark markets 2024
dark market darknet site darknet market links https://darknetmarketstore.com/ – dark web search engine
how to get on dark web deep web markets darknet seiten https://darknetmarketstore.com/ – darknet drug store
dark market onion darknet search engine dark web links https://darknetmarketstore.com/ – darknet markets 2024
onion market dark web sites links dark websites https://darknetmarketstore.com/ – deep web drug store
dark web access darkmarket 2024 dark web search engine https://darknetmarketstore.com/ – dark web links
the dark internet tor market links dark market url https://darknetmarketstore.com/ – free dark web
dark web sites dark web access darkmarket list https://darknetmarketstore.com/ – darkmarket 2024
dark web sites deep web drug links darknet site https://darknetmarketstore.com/ – tor marketplace
dark web links darkweb marketplace darkweb marketplace https://darknetmarketstore.com/ – best darknet markets
deep web markets deep web markets dark market url https://darknetmarketstore.com/ – darkmarket list
How to shop for cheap sale ugg boots SoftMoc, Sandale sport DAISY, rose, filles 'flash sale' under $140 best seller
Gasket Tools
Neoprene Faced Phenolic Gasket Kit
Mens Organic Yoga Pants
Neoprene Faced Phenolic Gasket Kits
Neoprene Gasket Kits
Buy quality cheap products womens ugg slippers SoftMoc, SoftMocs avec fourrure de lapin CUTE 5, noir noir, femmes 'clearance prices' under $110 buy online
Where to get discounted products cheap real uggs SoftMoc, SoftMocs avec fourrure de lapin CUTE 5, vert, femmes 'shop now' under $120 same day delivery
Yoga Pants Flare Leg
ブランドスーパーコピー
Mens Yoga Pants Kohls
Mens Yoga Dress Pants
http://www.catrinapuchary.pl
Long Flare Yoga Pants
Online best price deals ugg slippers sale SoftMoc, SoftMocs avec fourrure de lapin CUTE 5, bleu, femmes 'best shopping' under $130 in stock
Packing Tools
Where to find discounted products cheap ugg slippers SoftMoc, SoftMocs avec fausse fourrure de lapin CUTE 6 JR, gris, filles 'exclusive access' under $90 fast delivery
dark markets 2024 tor markets links darknet drug store https://darknetmarketstore.com/ – deep web drug markets
dark market 2024 darknet market list deep web drug markets https://darknetmarketstore.com/ – dark net
best darknet markets dark web market tor market https://darknetmarketstore.com/ – dark markets 2024
darknet market links blackweb official website tor darknet https://darknetmarketstore.com/ – dark markets
dark net dark web market list darknet marketplace https://darknetmarketstore.com/ – darknet market list
dark market list dark web link dark websites https://darknetmarketstore.com/ – free dark web
how to get on dark web bitcoin dark web darknet websites https://darknetmarketstore.com/ – onion market
dark market url deep web search dark market link https://darknetmarketstore.com/ – darkmarket
deep web markets darknet markets darknet marketplace https://darknetmarketstore.com/ – blackweb official website
tor markets darknet markets deep web search https://darknetmarketstore.com/ – darknet drug store
darkmarket link darkmarket list bitcoin dark web https://darknetmarketstore.com/ – black internet
tor darknet dark web market links the dark internet https://darknetmarketstore.com/ – dark market 2024
deep web drug markets darknet market links black internet https://darknetmarketstore.com/ – darknet site
dark website dark web search engines darkmarkets https://darknetmarketstore.com/ – darknet market lists
dark market list dark market onion dark web sites links https://darknetmarketstore.com/ – tor markets
black internet how to access dark web deep web drug markets https://darknetmarketstore.com/ – darkmarket url
dark market 2024 darknet links darknet market list https://darknetmarketstore.com/ – darknet market
darknet site darkmarket 2024 dark web links https://darknetmarketstore.com/ – deep web markets
tor markets links dark website dark web market links https://darknetmarketstore.com/ – darknet market lists
dark internet darknet search engine free dark web https://darknetmarketstore.com/ – tor dark web
deep web search tor markets 2024 deep web sites https://darknetmarketstore.com/ – darkmarkets
dark web sites links dark web drug marketplace drug markets onion https://darknetmarketstore.com/ – dark web search engines
dark websites tor dark web onion market https://darknetmarketstore.com/ – darkmarket list
dark net dark market url deep web drug url https://darknetmarketstore.com/ – darkmarket
dark markets 2024 dark web search engines darkmarket url https://darknetmarketstore.com/ – darkmarket url
darknet drugs tor market url how to access dark web https://darknetmarketstore.com/ – deep web drug links
deep web drug links dark web websites dark internet https://darknetmarketstore.com/ – darknet market list
darknet drug links dark markets 2024 darknet drug market https://darknetmarketstore.com/ – darknet market
how to access dark web dark web market the dark internet https://darknetmarketstore.com/ – dark markets 2024
dark web link darkmarkets dark web drug marketplace https://darknetmarketstore.com/ – darknet drugs
darkweb marketplace darknet seiten tor market https://darknetmarketstore.com/ – darknet markets 2024
tor market links darknet websites darknet marketplace https://darknetmarketstore.com/ – deep web drug links
drug markets dark web dark web search engines deep web drug url https://darknetmarketstore.com/ – how to get on dark web
Hard Floor Washer Cleaner
How to buy ugg mini bailey button boots adidas, adidas, Basket KAPTIR 3.0 K, gris rose violet, filles 'on sale now' under $200 quick delivery
How to find cheap deals ugg classic tall sale uk adidas, adidas, Basket GRAND COURT 2.0, blanc rose, femmes 'deal hunter' under $70 low price online
Floor Swipe
FABRIC REINFORCED INSERTION SHEETING
COMMERCIAL GRADE EPDM RUBBER SHEET
FKM RUBBER SHEETING
Floor Scourer
Buy cheap and original ugg boots pink sale adidas, adidas, Baskets à lacets VL COURT 3.0, encre légende blanc blanc, hommes 'promotions' under $60 great customer service
SILICONE RUBBER SHEETING
Where to shop for best deals ugg boot sale clearance adidas, adidas, Baskets VL COURT 3.0, blanc gris, femmes 'best offers online' under $80 buy in bulk
Commercial Tile Scrubber
ブランドスーパーコピー
How to find best discounts cheap ugg boots for kids adidas, adidas, Baskets VL COURT 3.0, blanc rose, femmes 'special pricing' under $50 best prices guaranteed
Task Pro Floor Scrubber
http://www.zolybeauty.nl
NEOPRENE RUBBER SHEETING
how to get on dark web tor market dark market https://darknetmarketstore.com/ – tor markets links
dark markets 2024 darknet drug market darknet search engine https://darknetmarketstore.com/ – dark web links
black internet dark web market list bitcoin dark web https://darknetmarketstore.com/ – darkmarket link
deep web drug links darknet drugs darknet seiten https://darknetmarketstore.com/ – dark market url
deep web drug store dark web drug marketplace darknet links https://darknetmarketstore.com/ – darknet marketplace
dark web search engines deep web drug links dark market 2024 https://darknetmarketstore.com/ – free dark web
blackweb the dark internet blackweb https://darknetmarketstore.com/ – best darknet markets
drug markets onion dark market url darkmarket list https://darknetmarketstore.com/ – deep dark web
darknet drug market tor market darknet site https://darknetmarketstore.com/ – darknet seiten
darknet links deep web drug store darknet market list https://darknetmarketstore.com/ – tor market
darknet site bitcoin dark web darknet marketplace https://darknetmarketstore.com/ – blackweb
darkmarket url dark web markets tor dark web https://darknetmarketstore.com/ – dark web market list
tor darknet dark web search engine deep web drug markets https://darknetmarketstore.com/ – darknet marketplace
darkmarket link dark market link how to access dark web https://darknetmarketstore.com/ – tor markets links
How to get cheap products leather ugg boots uk SoftMoc, Pantoufle à talon ouvert CADEL 2, brun Crazy,homme 'premium products' under $100 low price discounts
Where to buy discounted products ugg uk sale SoftMoc, Pantoufles à talon ouvert CADEL 2, gris, hommes 'cheap goods' under $80 unbeatable online prices
Styrene-butadiene rubber gasket
Disc Water Filter
Agricultural Spray Nozzles
316 304 Stainless Steel Sintered Wire Mesh Filter Disc
Pure White PTFE Gasket
Shop online for discounts mini ugg boots SoftMoc, Pantoufle à dos ouvert CADEL 2, châtaigne, hommes 'best online bargains' under $70 trending online sales
Acid & alkali-resisting rubber gasket
Fog Mist Spray Nozzle
Online shopping for authentic uggs uk sale SoftMoc, Pantoufle à talon ouvert BRIE, gruau, femme 'super shopping' under $90 best product deals
http://www.edzokepzo.hu
SBR rubber gasket
Coffee Tray Filter Screen
ブランドスーパーコピー
Best place to shop online chestnut ugg boots SoftMoc, Sandale sport CALEY3, noir blanc, femmes 'exclusive shopping' under $60 premium deals
Folding shape PTFE envelope gasket
dark market 2024 dark market bitcoin dark web https://darknetmarketstore.com/ – dark net
dark web search engine deep dark web onion market https://darknetmarketstore.com/ – darknet market lists
darkmarket 2024 deep web sites how to access dark web https://darknetmarketstore.com/ – dark web sites
dark net dark web search engine deep web drug markets
dark web site dark market link darknet drug market
dark web links blackweb dark web websites
tor market onion market tor markets links
Nitrile Rubber
Best way to buy ugg bailey button chestnut UGG, Botte NEUMEL PLATFORM CHELSEA, femmes 'popular shopping' under $190 customer favorites
ブランドスーパーコピー
Oval Ring Joint Gasket
Get the best price ugg boots uk size UGG, Sandale AWW YEAH EVA, noir, femmes 'hot offers' under $50 buy direct
Bug Zapper Outdoor Electronic Mosquito Zapper
Stop itching water
Rechargeable Mosquito Zapper
Viton rubber sheet
Moist repellent patch
Portable Bug Zapper
Where to get ugg boots for kids sale uk UGG, Botte CLASSIC MINI PLATFORM, noir, femmes 'quick sale' under $200 best offer
Octagonal Ring Joint Gasket
china Nitrile Rubber sipplier
Cheapest online deals ugg short boots sale UGG, Botte CLASSIC ULTRA MINI PLATFORM, noir, femmes 'exclusive deals' under $180 online bargains
How to find classic tall ugg boots sale UGG, Botte CLASSIC ULTRA MINI PLATFORM, châtaigne, femmes 'flash deals' under $170 great savings
ncthp.dgweb.kr
dark web sites links onion market tor market
the dark internet dark web sites links blackweb official website
darknet market dark web market links deep web search
dark market url dark web sites dark market 2024
dark markets dark internet darknet site
blackweb dark web market links darkmarket link
darkweb marketplace darknet market links darknet market
darknet links tor markets darknet market links
dark web link darkmarket darkweb marketplace
darkmarket url darknet markets 2024 darknet sites
darknet drug links dark market list tor market url
deep web links tor markets blackweb
darknet seiten black internet darknet drugs
dark markets 2024 darknet markets 2024 darknet websites
darknet markets darknet search engine deep web drug markets
Wow superb blog layout How long have you been blogging for you make blogging look easy The overall look of your site is magnificent as well as the content
tor markets 2024 darknet market tor market
Where to purchase cheap genuine uggs uk Crocs, Sabot de confort SQUISHMELLOW CLASSIC EVA, multi, femmes 'low prices' under $200 premium products
Where to buy cheap ugg shopping online Crocs, Sabot de confort CLASSIC FUN LAB, atmosphère, tout-petits 'exclusive products' under $60 best discount deals
ブランドスーパーコピー
Smart Lock For Home
1000X2000MM Black Blue Pa6 Pa66 Board
Chain Lock
Insulation Epoxy Glass Sheet FR4 Grade
Affordable shopping kids ugg boots clearance Crocs, Flâneur à plateforme STOMP EVA, noir noir, femmes 'trending products' under $80 bulk purchase discounts
Different Color Nylon Panel
Where to find cheap ugg leather boots uk Crocs, Sabot de confort CLASSIC LINED PUFFER, noir, femmes 'best products' under $70 quick processing
High wear-resistant MC Nylon Board
santoivo.com.br
Buy authentic products ugg footwear Crocs, Sandale à enfiler BROOKLYN LUXE, noir, femmes 'best quality items' under $50 buy today
Best polishing Nylon cnc parts
Smart Door Lock
Lock Case
Deadbolt
tor market links deep web drug store dark market url
darknet drug market onion market the dark internet
darknet markets 2024 deep web drug links free dark web
how to get on dark web tor market url drug markets onion
darkmarket 2024 deep web drug markets darkmarkets
dark web search engine deep web markets black internet
darknet search engine darknet drug links darkmarket 2024
tor market links dark web access dark web websites
darkmarket link darkmarket 2024 tor markets
tor market dark web websites dark web links
bitcoin dark web blackweb dark websites
tor marketplace drug markets onion bitcoin dark web
darknet market list deep web drug url tor dark web
darknet drug links dark market dark market 2024
darknet drug store dark market darknet search engine
blackweb official website black internet dark websites
onion market dark websites darknet drug market
tor marketplace tor dark web dark web link
darkmarkets dark web drug marketplace deep web markets
darknet market links deep web drug store darkmarket list
darknet sites dark web market list darkmarket link
deep web drug links deep web sites best darknet markets
can priligy cure pe It s too early in my journey to tell exactly what type of doctor he will be but I am hoping for the best
CHINA Full Automatic Camprofile Grooving Gasket Making Machine MANUFACTURE
Outdoor swing chair designs
Best online stores ugg slipper sale Blundstone, Unisex 550 Classic Chelsea Boot – Walnut 'hot sales' under $180 e-commerce discounts
Spiral Wound Gasket Metal Ring Bending Machine
Find best prices ugg boots for sale uk Blundstone, Unisex 510 Orginal Chelsea Boot – Black 'exclusive products' under $100 trending discounts
china Spiral Wound Gasket Metal Ring Bending Machine manufacture
Best Outdoor Lounge Furniture
Camping
How to buy affordable ugg shoes sale Blundstone, Unisex 531 Classic Twin Gore Boot – Black 'low prices' under $80 store promotions
Best Outdoor Furniture Uk
china Spiral Wound Gasket Metal Ring Bending Machine supplier
Best outdoor table options
How to buy discounted ugg men sale Blundstone, Unisex 558 – Classic Chelsea Boot – Black 'high demand' under $190 best value shopping
Online shopping deals ugg boots size chart Blundstone, Unisex 500 Original Chelsea Boot- Stout Brown 'top picks' under $170 free shipping on all purchases
http://www.plot28.com
ブランドスーパーコピー
CHINAFull Automatic Camprofile Grooving Gasket Making Machine SUPPLIER
darknet market darkmarket url best darknet markets
darkmarket dark market onion tor market links
deep web search darknet market links black internet
dark web websites tor markets dark internet
deep web sites how to get on dark web tor market url
deep dark web dark web market links tor market links
deep web drug store darknet drug market dark website
darkmarket link dark web search engine deep web drug store
deep web drug markets dark web drug marketplace deep web links
dark market darknet links darknet site
darknet markets darknet seiten darknet market links
dark market onion darkmarket list bitcoin dark web
black internet darknet market lists https://darknetmarketstore.com/ – deep web markets
dark web link dark market 2024 https://darknetmarketstore.com/ – darknet site
deep dark web darknet drug links https://darknetmarketstore.com/ – dark net
dark web drug marketplace how to access dark web https://darknetmarketstore.com/ – dark web drug marketplace
deep web drug markets dark web sites https://darknetmarketstore.com/ – how to access dark web
dark website free dark web https://darknetmarketstore.com/ – dark web market links
nhny86
Cheap Authentic ugg bailey button classic short sale SoftMoc, Women's Wensy 02 Vegan Sandal – Nude 'best deals' under $170 huge discounts online
Achromatic Spherical Mirror
Mica Paper
Large Ruby Crystal
Mica Tube
Mica Roll
Mica Tape
Mica Plate
haedang.vn
How to get ugg boots sale genuine SoftMoc, Women's Wednesday 02 Vegan Waterproof Boot – Black 'affordable prices' under $140 buy high demand products
Photodiode
Blue Sapphire Crystal
Laser Crystal Materials
Buy now ugg boots classic short sale 2024 SoftMoc, Women's Wensy 02 Vegan Sandal – White 'top quality' under $150 fast delivery deals
Best place to buy ugg leather boots sale SoftMoc, Women's Wednesday 01 Vegan Waterproof Boot – Black 'buy now' under $160 fast payment options
Original Cheap ugg winter sale SoftMoc, Women's Wendy Tailored Slipon Shawl Loafer – Black Patent 'top-rated deals' under $180 limited time sales
ブランドスーパーコピー
dark websites drug markets dark web https://darknetmarketstore.com/ – tor darknet
deep web drug links darknet drug market https://darknetmarketstore.com/ – darknet drug links
deep web drug links deep web links https://darknetmarketstore.com/ – darknet websites
blackweb official website darknet market lists https://darknetmarketstore.com/ – drug markets dark web
dark market url deep web links https://darknetmarketstore.com/ – dark web sites
dark markets darknet markets 2024 https://darknetmarketstore.com/ – darknet search engine
darknet market tor marketplace https://darknetmarketstore.com/ – deep web sites
darknet site deep web drug store https://darknetmarketstore.com/ – darkmarkets
darknet websites dark market https://darknetmarketstore.com/ – darknet drugs
dark web market darknet market https://darknetmarketstore.com/ – tor markets links
darknet markets 2024 tor markets links https://darknetmarketstore.com/ – darknet market list
darknet drug store darknet seiten https://darknetmarketstore.com/ – tor dark web
dark websites deep web markets https://darknetmarketstore.com/ – tor markets 2024
darknet market links onion market https://darknetmarketstore.com/ – dark net
dark market 2024 darknet market lists https://darknetmarketstore.com/ – dark web site
dark web market links darknet seiten https://darknetmarketstore.com/ – dark market url
tor markets links dark market onion https://darknetmarketstore.com/ – bitcoin dark web
dark web sites dark web site https://darknetmarketstore.com/ – free dark web
darkmarket url black internet https://darknetmarketstore.com/ – darkweb marketplace
dark markets 2024 darknet drugs https://darknetmarketstore.com/ – best darknet markets
tor market url darknet drug links https://darknetmarketstore.com/ – tor markets links
darkmarkets darknet site https://darknetmarketstore.com/ – dark market
darkweb marketplace deep web drug links https://darknetmarketstore.com/ – tor markets 2024
dark web market list deep web drug url https://darknetmarketstore.com/ – darknet sites
tor marketplace darkmarket link https://darknetmarketstore.com/ – dark web access
dark web market list darknet search engine https://darknetmarketstore.com/ – darkmarkets
dark web markets darkmarket https://darknetmarketstore.com/ – dark web search engines
dark market url deep web drug url https://darknetmarketstore.com/ – tor markets
dark market list darknet sites https://darknetmarketstore.com/ – darknet seiten
darkmarkets dark web sites links https://darknetmarketstore.com/ – how to access dark web
tor market url darknet markets https://darknetmarketstore.com/ – darknet sites
deep web markets darknet search engine https://darknetmarketstore.com/ – dark web market links
tor markets darknet marketplace https://darknetmarketstore.com/ – drug markets onion
dark market darkmarket https://darknetmarketstore.com/ – darknet drug market
blackweb dark web market links https://darknetmarketstore.com/ – darknet drug store
darkmarket list drug markets onion https://darknetmarketstore.com/
dark web sites deep web drug store https://darknetmarketstore.com/
darkmarket list dark markets https://darknetmarketstore.com/
deep web search deep web sites https://darknetmarketstore.com/
Very soon this site will be famous among all blogging
people, due to it’s nice content
dark market url darkmarket 2024 https://darknetmarketstore.com/
darknet markets darknet marketplace https://darknetmarketstore.com/
dark web websites dark web search engines https://darknetmarketstore.com/
darknet market darkmarket https://darknetmarketstore.com/
darkmarket blackweb official website https://darknetmarketstore.com/
dark market link tor darknet https://darknetmarketstore.com/
darkweb marketplace tor dark web https://darknetmarketstore.com/
deep web sites dark web search engines https://darknetmarketstore.com/
deep web drug links darknet search engine https://darknetmarketstore.com/
darknet markets 2024 dark web link https://darknetmarketstore.com/
deep web drug markets how to access dark web https://darknetmarketstore.com/
darknet search engine onion market https://darknetmarketstore.com/
deep web drug url deep web drug url https://darknetmarketstore.com/
dark web websites darknet site https://darknetmarketstore.com/
drug markets dark web dark markets https://darknetmarketstore.com/
deep web markets tor dark web https://darknetmarketstore.com/
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to
my log that automatically tweet my newest
twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe
you would have some experience with something like this.
Please let me kniw if you run into anything.
I truly enuoy reading you blog annd I look forward to your new updates. https://www.waste-ndc.pro/community/profile/tressa79906983/
dark website tor market https://darknetmarketstore.com/
darkmarket url dark market url https://darknetmarketstore.com/
dark web site the dark internet https://darknetmarketstore.com/
darknet search engine darkweb marketplace https://mydarknetmarketlinks.com/
tor markets the dark internet https://mydarknetmarketlinks.com/
darknet market lists tor markets 2024 https://mydarknetmarketlinks.com/
darknet marketplace dark web websites https://mydarknetmarketlinks.com/
deep web drug store darknet websites https://mydarknetmarketlinks.com/
deep web links darknet market lists https://mydarknetmarketlinks.com/
dark net darknet market list https://mydarknetmarketlinks.com/
onion market best darknet markets https://mydarknetmarketlinks.com/
dark market list tor dark web https://mydarknetmarketlinks.com/
dark internet tor darknet https://mydarknetmarketlinks.com/
darknet links deep web drug store https://mydarknetmarketlinks.com/
tor markets dark web market list https://mydarknetmarketlinks.com/
onion market tor market url https://mydarknetmarketlinks.com/
darknet links blackweb https://mydarknetmarketlinks.com/
dark web links dark web search engine https://mydarknetmarketlinks.com/
darknet sites darknet market https://mydarknetmarketlinks.com/
darknet search engine darknet drug links https://mydarknetmarketlinks.com/
dark market list darkweb marketplace https://mydarknetmarketlinks.com/
How to get cheap products men uggs SteveMadden, Bottine imperméable DRESDENN, brun, hommes 'special pricing' under $100 bulk purchase discounts
Best prices for goods ugg sale boots SteveMadden, Bottine imperméable DRESDENN, noir, hommes 'trendy items' under $200 limited time promotion
Online best price deals ugg evera SteveMadden, Baskets à lacets ELEVATE 2, blanc noir, femmes 'shop for savings' under $130 big deals
3021 Phenolic Paper Laminated Sheet
Where to get discounted products ugg classic SteveMadden, Sandale compensée ESTER, noir, femmes 'low-cost deals' under $120 only a few left
Fold Up Electric Mobility Scooter
Buy cheap fashion womens uggs SteveMadden, Flâneur décontracté DRAKO 1, noir, femmes 'best price guaranteed' under $180 trending products online
ブランドスーパーコピー
3 Wheel Foldable Electric Scooter For Adults
http://www.abilitytrainer.cloud
Enclosed Electric Scooters
Electric 3 Wheel Scooter With Seat
Travel Scooters For Adults
POM Sheet
Phenolic Laminated Sheet
POM ROD
3025 Phenolic Cotton Laminated Sheet
dark web market list best darknet markets https://mydarknetmarketlinks.com/
onion market drug markets dark web https://mydarknetmarketlinks.com/
deep web drug store deep web links https://mydarknetmarketlinks.com/
deep web markets drug markets onion https://mydarknetmarketlinks.com/
dark web market list bitcoin dark web https://mydarknetmarketlinks.com/
dark market 2024 darknet links https://mydarknetmarketlinks.com/
dark market url dark web sites https://mydarknetmarketlinks.com/
darknet market list darknet market links https://mydarknetmarketlinks.com/
darknet market darknet drug store https://mydarknetmarketlinks.com/
darknet websites how to access dark web https://mydarknetmarketlinks.com/
dark web drug marketplace the dark internet https://mydarknetmarketlinks.com/
best darknet markets deep dark web https://mydarknetmarketlinks.com/
darkmarket list dark web search engine https://mydarknetmarketlinks.com/
darknet search engine darknet drug market https://mydarknetmarketlinks.com/
dark market onion tor markets https://mydarknetmarketlinks.com/
best darknet markets tor darknet https://mydarknetmarketlinks.com/
how to get on dark web deep dark web https://mydarknetmarketlinks.com/
dark web site darknet drug market https://mydarknetmarketlinks.com/
darkmarket list black internet https://mydarknetmarketlinks.com/
Men,S Razor
Get best discounts wedge ugg boots Converse, Kids' Chuck Taylor All Star Hi Top Sneaker – White 'hurry up' under $80 online exclusive
1000X2000MM Black Blue Pa6 Pa66 Board
Discounted items male ugg boots Converse, Kids' Chuck Taylor All Star Sneaker – White 'flash deals' under $100 holiday sales
ブランドスーパーコピー
Best polishing Nylon cnc parts
Disposable Barber Razor
Online cheap deals ankle ugg boots Converse, Kids' Chuck Taylor All Star Sneaker – Red 'on sale now' under $90 special promotions
Razor
Different Color Nylon Panel
Private Label Razor Blades
Get deals on ugg america Converse, Girls' Chuck Taylor All Star Sneaker – Pink 'hot offers online' under $180 popular items
Insulation Epoxy Glass Sheet FR4 Grade
id98786332.myjino.ru
Disposable Razor For Barber
Best discount deals ugg shoes for women Converse, Women's Chuck Taylor All Star Shoreline Sneaker- White 'best shopping' under $200 buy with discounts
High wear-resistant MC Nylon Board
darkmarket darkmarket url darknet drug links
drug markets onion dark internet darkmarket url
deep web drug markets bitcoin dark web black internet
darknet site deep web sites darknet market links
darknet seiten darknet drugs darknet websites
dark web search engine darknet marketplace darknet market lists
tor markets 2024 tor markets 2024 darknet drugs
dark web drug marketplace tor market links dark net
darknet websites how to get on dark web tor darknet
drug markets dark web onion market onion market
deep dark web deep web links dark net
tor market dark web search engines dark web access
deep web drug url dark market 2024 darkmarket 2024
deep web drug store dark web link darkmarket link
dark market list blackweb dark markets
dark market 2024 tor markets darknet drug market
dark market 2024 bitcoin dark web deep web drug markets
dark web market links dark net dark web sites
the dark internet darknet market list dark web drug marketplace
darknet sites dark web market dark web search engines
dark web link tor marketplace darknet markets 2024
black internet dark web links blackweb
dark market url dark websites darkmarket url
darkmarket 2024 tor dark web dark web access
darknet site tor markets dark market 2024
darkmarket 2024 darkweb marketplace dark web markets
dark market list dark market 2024 dark market list
darknet search engine dark markets 2024 dark web market links
dark websites darknet site tor market
dark web market links dark web sites dark web market list
tor markets links darknet market dark market list
deep web links darkmarket url how to access dark web
dark web site deep web drug markets dark web search engine
deep web drug markets tor dark web darknet drug store
black internet dark market 2024 dark web market
darknet drugs darkmarket url dark market
darknet market lists dark market link dark market link
drug markets dark web dark web market best darknet markets
darknet markets deep web drug store deep web search
how to access dark web darkmarket 2024 tor marketplace
darkmarkets darknet market links deep web search
dark web links deep web drug links bitcoin dark web
darknet search engine deep web sites drug markets dark web
dark web search engine drug markets dark web deep web drug store
drug markets onion dark markets darkmarket 2024
how to get on dark web tor markets darknet drug market
dark websites deep dark web tor marketplace
darknet markets darkmarket link how to access dark web
tor darknet drug markets dark web dark web websites
dark web access dark web search engine darknet market lists
http://www.xn--h1aaasnle.su
EPDM Rubber Sheet
Buy products online for cheap ugg slippers for men Skechers, Girls' JGoldcrown Uno Lite Metallic Love Lace Up Sneaker – Hot Pink Multi 'huge discounts' under $160 fast shipping
Find affordable shopping ugg australia sale Skechers, Girls' JGoldcrown Uno Lite – Metallic Love Lace Up Sneaker – Black Gold 'super savings' under $180 hot deals
Asbestos Latex Sheet
ブランドスーパーコピー
Vacuum Mixer Machine
NBR Rubber Sheet
How to buy at a discount uggs boots Skechers, Girls' JGoldcrown Uno Lite Sneaker – Multi 'daily deals' under $200 customer reviews
Vacuum Mixer
Water Filling And Capping Machine
Chemical Mixing Machine
Non-Asbestos Latex Paper
Best online shopping offers ugg slippers women Skechers, Girls' JGoldcrown Uno Lite Lace Up Sneaker – White Pink Turquoise 'popular brands' under $140 limited time offer
Mixing And Filling Machine
Find the best product deals bailey button uggs Skechers, Girls' Twinkle Sparks Ice Princess Hi-Top Sneaker – Light Blue Multi 'shop today' under $150 exclusive products
SBR Rubber Sheet
darknet drugs dark market bitcoin dark web
deep web drug url dark web sites links dark web market
how to get on dark web deep web sites darknet drug store
dark web websites tor darknet how to get on dark web
the dark internet darkmarket 2024 deep web markets
tor markets links dark web market links black internet
dark web drug marketplace dark web site dark web sites links
dark web search engines drug markets onion blackweb
tor markets links dark web markets blackweb official website
deep web markets deep web drug links how to get on dark web
dark web sites dark internet dark markets
black internet darknet drug market tor darknet
darkmarket link deep web sites dark web websites
tor market url darkweb marketplace dark web search engines
dark web search engines darknet market lists darkweb marketplace
tor market links dark web drug marketplace darknet seiten
dark web sites dark web market blackweb
tor market links darknet websites dark markets
darknet drug store darknet site drug markets onion
dark web market links dark market darkmarket list
darkmarket list darkweb marketplace deep dark web
onion market onion market darkmarket url
tor markets links dark web markets dark web links
dark market darknet market list darknet drug store
darknet websites darknet markets 2024 dark web site
darkweb marketplace dark net dark internet
dark internet dark web link dark web link
dark internet dark market list darknet drugs
tor marketplace the dark internet deep web markets
dark markets 2024 dark website darkmarket list
dark market 2024 deep web sites tor markets links
tor marketplace deep web drug url onion market
bitcoin dark web dark web websites the dark internet
blackweb deep web sites tor market
free dark web darkweb marketplace free dark web
darknet seiten how to get on dark web darkmarket link
Leather Soccer Shoes
Asics Sports Shoes
http://www.sp-plus1.com
Black rubber sheet gasket
ブランドスーパーコピー
affordable trendy clothes best fall outfits K Neon Nirvana Camp Shorts trendy outfits deals styles under $80 style inspiration for women
quality fashion at low prices autumn fashion for women K Netherworld Nightlife High-Waisted Bottoms best discounts on fashion accessories under $15 trendy outfits near me
Insulating rubber gasket
rubber gasket
fast shipping fashion men's athletic wear K Never Plaid It So Good Leggings limited time fashion deals must-have items under $70 Nearby Shoe Stores
trendy clothing for less winter outfits for men K Never Let You Down Wide-Leg Jeans seasonal fashion promo clearance items under $50 Fast Shipping
Converse Shoes
U type PTFE envelope gasket
online shopping deals affordable women's shoes K Neon Nostalgia Cutout Bell Bottoms cheap clothing sale fashion under $100 unique clothing finds
Custom Shoes
Futsal Shoes
Fire-resistance rubber gasket
darknet market links deep web drug markets darkmarket
darknet markets 2024 drug markets onion blackweb
dark markets dark web site darknet market